관상이동법觀想移動法
54. 78수
171
이세돌 9단과 알파고의 4국에서 이 9단은 신의 한수 혹은 묘수라 불리는 역사적인 78수를 둔다. 이후 아자황 박사는 알파고의 지시에 따라 헛수라 불리는 수들을 두고 완벽에 가깝게 패하였다. 이후 이 9단은 인터뷰에서 78수는 사실 꼼수였다고 밝히며 이후 알파고의 대응은 일종의 버그였던것 같다고 농담처럼 이야기 했다. 이후 알파고의 전승을 예측했던 김진호 교수는 구글 딥마인드 측은 다섯번의 대국 가운데 네번째 대국이 져주기에 가장 적당하다 판단했고 알파고 대신 돌을 놓은 아자황 박사에게 일부러 오답을 보냈을 것” 이라고 주장했다. 알파고는 패배를 선언할 때 돌을 던지는 인간과 달리 스스로를 3인칭으로 “알파고는 기권한다(AlphaGo resigns)” 라는 팝업창을 띄웠다.
.
https://deepmind.com/alphago-vs-alphago
지난 해 이세돌 9단을 꺾었던 바둑 인공지능 ‘알파고(알파고 리·AlphaGo Lee)’를 100 대 0으로 제압한 인공지능 ‘알파고 제로(AlphaGo Zero)’가 나왔다.
개발자인 데미스 허사비스 구글 딥마인드 공동창업자는 국제학술지 ‘네이처’ 19일자에 알파고 제로 개발 소식을 알렸다. 그는 “알파고 시리즈 중 가장 강력한 버전”이라고 밝혔다.알파고 제로는 단 36시간의 학습만으로 알파고 리를 넘어서는 능력을 갖췄고, 대국에서는 100대 0 압승을 거뒀다.
알파고 제로는 기보 없이 ‘독학’으로 바둑을 배워 최강자의 자리에 올랐다. 기존 알파고 리는 16만 건 인간 바둑기사들의 기보 데이터를 학습하는 ‘딥 러닝’과 이를 기반으로 스스로 바둑을 두며 실력을 쌓는 ‘강화학습’을 통해 바둑을 배웠다. 이세돌을 이기기까지 12개월이란 긴 학습 시간을 보냈다. 지난 5월 세계 최강 바둑기사인 중국의 커제 9단을 누른 ‘알파고 마스터(AlphaGo Master)’는 학습 시간을 3분의 1 수준으로 줄였지만, 역시 기보를 통해 학습하는 과정을 거쳤다.
알파고 제로는 딥 러닝을 완전히 생략하고 강화학습만을 통해 70시간, 단 3일 만에 세계 최고 수준의 바둑 실력을 갖췄다. 그 시간 동안 혼자 490만 판의 바둑을 뒀다. 감동근 아주대 전자공학과 교수는 “적어도 바둑에 있어선 기존 인간의 지식을 입력해주지 않아도, 스스로 강화학습을 통해 인간을 넘어선 인공지능을 구현할 수 있음이 확인된 것”이라고 설명했다.
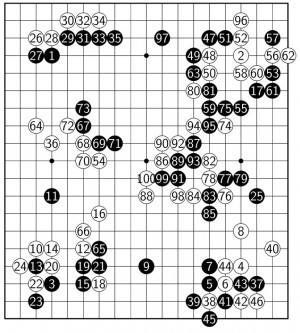
알파고 리(흑돌)와 알파고 제로(백돌)의 첫 번째 대국 기보. - 네이처 제공
이 때문에 알파고 제로는 훨씬 가벼워졌다. 알파고 리를 구동하기 위해선 176개의 그래픽프로세싱유닛(GPU·그래픽 연산 전용 프로세서)과 4개의 텐서프로세싱유닛(TPU·인공지능용 칩)이 필요했다. 반면 알파고 제로는 4개의 TPU 만으로 구동된다.
이정원 한국전자통신연구원(ETRI) 선임연구원은 “알파고 제로는 한 수를 둘 때 10만 번씩 시뮬레이션 하던 기존 알파고 리의 방식을 버렸다. 독학을 통해 스스로 바둑의 이론을 만들고, 이를 토대로 인간처럼 신중하게 한 가지의 수를 둔다”고 말했다.
딥마인드는 논문을 통해 현재까지 개발한 알파고 시리즈의 ‘엘로(ELO) 점수’를 공개했다. 엘로는 바둑 실력을 수치화한 점수다. 알파고 제로는 5185점, 알파고 마스터는 4858점, 알파고 리는 3739점을 받았다. 점수 차가 800점 이상이면 승률은 100%, 677점일 땐 99%, 366점 높다면 90% 승리한다는 의미다. 알파고 제로는 알파고 마스터와의 경기에서는 89대 11로 승리를 거뒀다.
이 연구원은 “인간이 만든 기존 바둑 이론을 버렸기 때문에 알파고 제로가 오히려 똑똑해진 것”이라며 “수천 년 간 인간과 함께 쌓여온 바둑이론이 오히려 창의적인 새로운 ‘수’의 탄생을 막았을 수도 있다는 것이 알파고 제로를 통해 증명된 것”이라고 설명했다.
허사비스 공동창업자는 “알파고 제로는 인간의 도움 없이도 새로운 지식을 발견하고, 통상적이지 않은 전략을 개발했다”며 “알파고가 개발된 지 2년 만에 나온 성과여서 인공 지능이 사람의 독창성을 넘어설 수 있다고 확신한다”고 말했다.
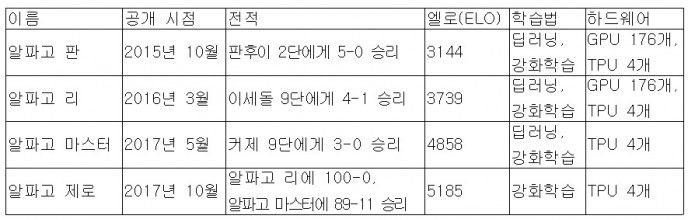
알파고 시리즈의 성능 비교. 엘로(ELO)는 바둑 실력을 수치화한 점수로 클수록 고수. GPU와 TPU는 각각 그래픽 연산 전용 프로세스와 인공지능용 칩을 말한다. - 네이처 제공